





Vor knapp einem Jahr haben wir untersucht, wie viele Websites in Deutschland AI-Bots blockieren. Wir finden: Es ist Zeit für eine Aktualisierung, denn im letzten Jahr ist einiges passiert. Und so haben wir uns drangesetzt und erneut die Top-1.000-Websites in Deutschland sowie die Websites der DESI250 angesehen. Unsere Datenbasis haben wir aber noch einmal vergrößert und zusätzlich die Top-10.000-Domains in Deutschland laut Sistrix untersucht. Und es zeigt sich ein interessantes Ergebnis.
Methodik:
- Identifikation der Top-1.000-Websites in Deutschland
- Analyse der DESI250
- Analyse der Top-10.000-Domains in Deutschland (laut Sistrix)
- Untersuchung der robots.txt jeder Website dahingehend, ob einer der ausgewählten 31 AI-Bots blockiert wurde
- Ausschluss von Websites aus der Analyse, die keine robots.txt haben oder wo diese nicht zugänglich war
- Vergleich mit den Daten aus dem vergangenen Jahr
Untersuchte Bots: Amazonbot, anthropic-ai, Applebot-Extended, Bytespider, CCBot, ChatGPT-User, ClaudeBot, Claude-Web, cohere-ai, Diffbot, FacebookBot, facebookexternalhit, FriendlyCrawler, Google-Extended, GoogleOther, GoogleOther-Image, GoogleOther-Video, GPTBot, ICC-Crawler, ImagesiftBot, img2dataset, Meta-ExternalAgent, OAI-SearchBot, omgili, omgilibot, PerplexityBot, PetalBot, Scrapy, Timpibot, VelenPublicWebCrawler, YouBot
Statistiken:
- Vollendet am 30.08.2023, 22.09.2023 und 17.09.2024
- Untersuchung von 1.153 Websites bzw. 1.100 robots.txt für den Vorjahresvergleich
- Untersuchung von 10.156 Websites bzw. 10.012 robots.txt für die Analyse mit erweiterter Datenbasis
Wie viele deutsche Webseiten schließen die Crawler aktuell aus?
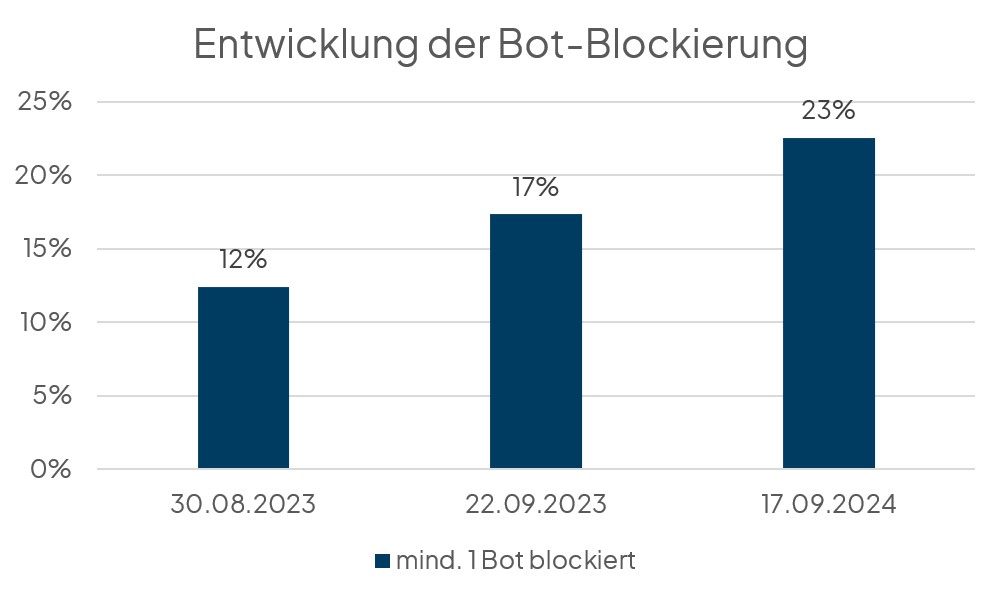
Insgesamt haben 22,5 % der untersuchten robots.txt mindestens einen der untersuchten Bots (hier nur: CCBot, GPTBot und ChatGPT-User) blockiert. Dabei waren es in der ersten Untersuchung nur 12,4 % und in der zweiten Untersuchung 17,4 %. Der Anteil ist also weiter angestiegen.
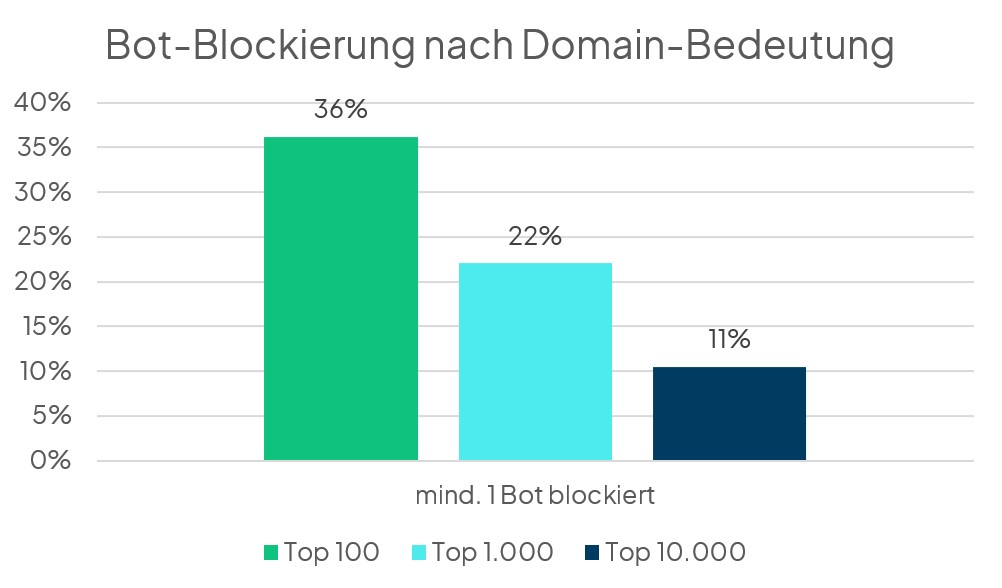
Da wir in diesem Jahr aber die Datenbasis noch einmal erweitert haben (es wurden mehr Websites und mehr Bots analysiert), können wir hier sogar noch tiefer einsteigen. So haben von den insgesamt 10.012 untersuchten Domains nur 11 % die untersuchten KI-Bots analysiert. Wie kann das sein? Dazu haben wir die Domains in Top 100, Top 1.000 und eben Top 10.000 (bzw. 10.012) unterteilt. Und dabei zeigt sich: Je populärer die Domain ist, desto höher ist die Wahrscheinlichkeit, dass mindestens ein KI-Bot blockiert wird.
Von den im letzten Jahr untersuchten Bots war der GPTBot der am häufigsten blockierte. Das ist auch weiterhin der Fall, selbst bei Betrachtung aller 31 nun untersuchten Bots.
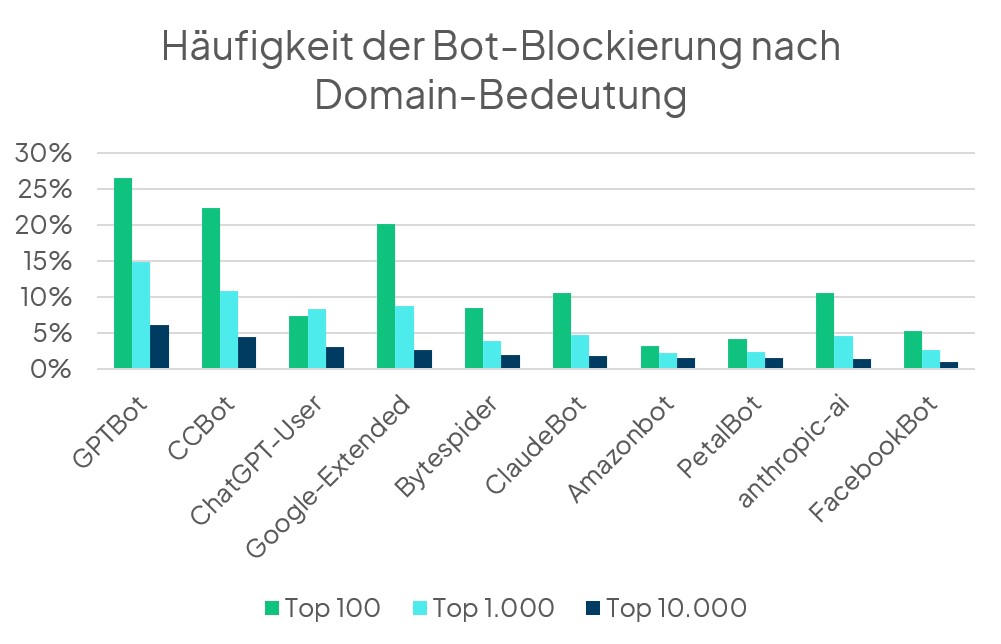
Betrachtet man alle untersuchten Domains, so blockieren nur 6 % der Domains den GPTBot. Die von allen Domains am häufigsten blockierten Bots sind GPTBot, CCBot, ChatGPT-User, Google-Extended und Bytespider. Unter den Top–100–Domains werden ClaudeBot und anthropic-ai häufiger blockiert als ChatGPT-User und Bytespider. Es werden also vorrangig LLM-Crawler blockiert.
Was machen diese Bots?
- GPTBot (von OpenAI) wird genutzt, um OpenAIs Sprachmodelle zu trainieren, d.h. hiermit werden ganze Domains gecrawlt. 1 [LLM Crawler]
- CCBot (von Common Crawl, einer NGO) crawlt Websites im großen Stil, um sie anderen zur Verfügung zu stellen. Die meisten bekannten Sprachmodelle basieren auf diesen Daten.2 [LLM Crawler]
- ChatGPT-User (von OpenAI) wird für Aktionen innerhalb von ChatGPT genutzt, z.B. zum Aufrufen von Webseiten oder bestimmter Inhalte, mit denen ChatGPT nicht trainiert wurde.3 [RAG Crawler]
- Google-Extended (von Google) wird genutzt, um Googles Sprachmodelle zu trainieren, z.B. Vertex AI oder Gemini.4 [LLM Crawler]
- Bytespider (von ByteDance, dem gleichen Inhaber wie von TikTok) wird genutzt, um diverse Sprachmodelle, vor allem im chinesischen Raum, zu trainieren.5 [LLM Crawler]
- ClaudeBot (von Anthropic) wird genutzt, um das Sprachmodell Claude von Anthropic zu trainieren. 6 [LLM Crawler]
- anthropic-ai (von Anthropic) wird ähnlich genutzt die ClaudeBot.7 [LLM Crawler]
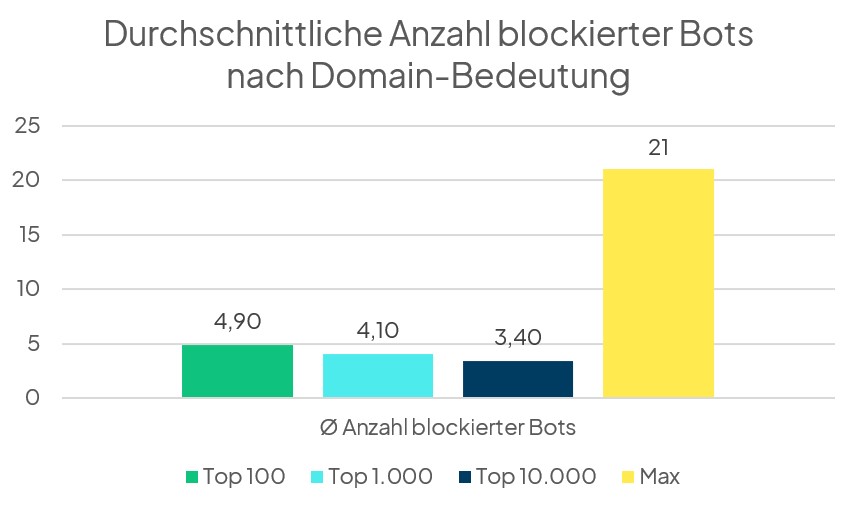
Wenn Domains sich entscheiden, dass sie KI-Bots blockieren, dann blockieren sie durchschnittlich drei Crawler. Unter den Top 100 Domains liegt der Durchschnitt bei 4,9 Bots. Das heißt, Domains mit höherem Sichtbarkeitsindex blockieren also nicht nur wahrscheinlicher überhaupt KI-Bots in der robots.txt, sondern auch mehr. Unter allen analysierten Websites gibt es zwei Domains, die jeweils sogar 21 der untersuchten Bots blockieren.
Key Facts auf einen Blick:
- 1.066 Websites (11 %) blocken mindestens 1 der untersuchten Bots
- Der Anteil steigt, je besser die Domain laut Sistrix performt: Bei den Top-100-Domains liegt der Anteil bei 36 %.
- Der Anteil der Bots blockierenden Websites stieg innerhalb eines Jahres von 12 % auf 23 % (Untersuchung von 1.100 Websites).
- Der am häufigsten blockierte AI-Bot ist GPTBot (mit 6 % der Top-10.000-Domains und 27 % der Top-100-Websites).
- Weitere häufig blockierte Bots sind: CCBot, ChatGPT-User, Google-Extended, Bytespider, ClaudeBot und anthopic-ai.
Warum sollte man KI-Crawler aussperren?
Large Language Models (LLMs) wie Googles Gemini oder Open AIs GPT-4 brauchen Daten, aus denen sie lernen können. Dafür wurden in der Vergangenheit bereits diverse Quellen herangezogen, u. a. Wikipedia, Bücher und gecrawlte Webseiten.
Diese gecrawlten Webseiten basieren z. B. auf verlinkten URLs auf Reddit mit mind. 3 Upvotes und auf dem Datenset der Non-Profit-Organisation Common Crawl. Dieser Bot crawlt wohl das gesamte World Wide Web. Es gibt hier also schon vorhandene Datensets, sodass deine Website vermutlich bereits dort enthalten ist.
Der User-Agent von Common Crawl ist der CCBot. Er kann durch die robots.txt blockiert werden. Das verhindert allerdings nur, dass die eigene Website künftig durch den Common Crawler durchstöbert wird. Die bereits vorhandenen Daten gehen dadurch nicht verloren.
Neuere Versionen der LLMs greifen jedoch nun selbst auf das Internet zu, um auch aktuelle Informationen liefern zu können. Möchte man keine solchen KI-Bot-Besuche auf der Website, kann man ihnen den Zugriff blockieren, um zu verhindern, dass die KI-Crawler neue Inhalte auslesen. Für ChatGPT heißt der User-Agent dieses Plugins beispielsweise „ChatGPT-User“. Auch hier gilt aber: Ältere Daten hat sich der Crawler bereits gesichert und rückt sie nicht wieder raus.
Was kannst du also tun, wenn dein Website-Content nicht in KI-generierten Antworten erscheinen soll? Es gibt mehrere Möglichkeiten, das zu erreichen:
- Ausschluss der KI-Crawler per robots.txt
- Serverseitiges Blockieren von IP-Adressen
- Ausspielen der Daten per Meta-Robots-Tag verhindern
Wie kann man KI-Bots ausschließen
Ausschluss der KI-Crawler per robots.txt
Konkret kannst du folgende Instruktionen in die robots.txt integrieren (hier am Beispiel des CCBot):
User-agent: CCBot
Disallow: /
Es muss nicht die gesamte Website vom Crawling ausgeschlossen werden. Es ist auch möglich, nur bestimmte Bereiche der Website zu sperren, z. B. durch
User-agent: CCBot
Disallow: /verzeichnis-4/
Du könnest also mit Hilfe der Logfiles herausfinden, welche KI-Crawler regelmäßig auf deine Seite zugreifen, und diese dann gezielt aussperren.
Cloudflare bietet als Content-Delivery-Network (CDN) inzwischen die Möglichkeit, per One-Click alle KI-Bots auf einmal auszusperren8. Das erleichtert Websitebetreibenden natürlich die Arbeit.
Serverseitiges Blockieren der IP-Adressen von KI-Crawlern
Neben den User-Agents gibt es auch die Möglichkeit, bekannte IP-Adressen vom Crawling auszuschließen. Das lässt sich für Außenstehende jedoch nicht nachprüfen. Darüber hinaus muss regelmäßig sichergestellt werden, dass die IP-Adressen der betreffenden Crawler noch aktuell sind. Außerdem sind nicht von allen KI-Crawlern die IP-Adressen bekannt.
Ausspielung der Daten per Meta-Robots-Tag verhindern
In den oben genannten Fällen werden deine Website-Inhalte also gar nicht ausgelesen (es sei denn, die Daten wurden bereits vor der Einstellung ausgelesen und sind bereits in Datenbanken vorhanden). Es gibt aber auch die Möglichkeit, die LLMs daran zu hindern, deine Daten für das Ausspielen von KI-Antworten zu nutzen.
Dazu kannst du pro URL den Meta-Robots-Tag „nosnippet“ setzen. Das bewirkt, dass zu dieser URL überhaupt keine Daten mehr in den Suchergebnissen angezeigt werden: keine KI-generierten Antworten, aber auch keine normalen Suchergebnis-Snippets, Featured Snippets oder Google Discover. In den meisten Fällen wirst du das nicht wollen. Daher ist diese Variante nur für einzelne URLs relevant.
Welche AI-Crawler sollte ich aussperren?
Auf diese Frage gibt es nur eine Antwort mit begrenzter Haltbarkeit. Denn ständig kommen neue Bots hinzu – entweder weil es neue Marktbeteiligte gibt (z. B. Plattformen oder Tools), oder weil bestehende Unternehmen neue Bots verwenden.
So haben wir in der Analyse vor einem Jahr beispielsweise nur den GPTBot, ChatGPT-User und CC-Bot untersucht. Dieses Mal haben wir uns bereits 31 Crawler angesehen. Das bedeutet, dass das Aussperren per robots.txt keineswegs eine einmalige Aktion ist, sondern mit einem regelmäßigen Aufwand verbunden bleibt. Es muss ständig geprüft werden, welche neuen Crawler dazukommen. Das kann z. B. anhand deiner Logfiles einsehen, da dort die User-Agents aufgeführt werden, die auf deine Website zugreifen.
Solltest du die AI-Crawler in der robots.txt wirklich aussperren?
Diese Frage lässt sich nicht so leicht beantworten, denn dafür gibt es kein für alle Anwendungsfälle gleichermaßen funktionierendes Patentrezept. Am Ende musst du diese Entscheidung selbst treffen, aber wir geben dir gern einige nützliche Hilfestellungen mit.
Zunächst müssen wir zwischen LLM-Crawlern, RAG-Crawlern und allgemeinen Web-Crawlern unterscheiden.
- LLM-Crawler nutzen eine vorhandene Datenbasis, um eine Sprache zu verstehen. Beispiele sind der bereits genannte CCBot oder auch der GPTBot.
- RAG-Crawler (RAG steht für Retrieval-Augmented Generation, d. h. „durch Abruf verstärkte Generierung“) ergänzen die vorhandenen Daten der LLMs (Sprache und Wissen) mit aktuellem und tieferem Wissen. Beispiele sind der ChatGPT-User und der PerplexityBot.
- Allgemeine Web-Crawler haben eigentlich eine andere Aufgabe, werden aber teilweise auch für KI-Produkte genutzt. Beispiele sind GoogleOther und der Amazonbot.
Lässt du nun das Crawling deiner Website zu, können diese Bots deine Inhalte auslesen und sie zum Trainieren des Sprachverstehens nutzen – sie können aber darüber hinaus deine Webseiten-Inhalte in ihren Programmen ausspielen.
So könnten deine Webseiten-Inhalte z. B. in den AI Overviews oder auch in ChatGPT ausgespielt werden. In den AI Overviews würde deine Webseite dann als Quelle genannt und auch verlinkt werden. Diese Art des Ausspielens wäre der von Featured Snippets also sehr ähnlich. Der einzige Unterschied: Die Inhalte der AI Overviews passen besser zur spezifischen Suchanfrage der Nutzenden. Das heißt: Du kannst dazu beitragen, dass die Nutzenden mit ihrem jeweiligen Sucherlebnis zufrieden sind. Wenn sie für weitere Infos noch auf deine Webseite klicken, habt ihr beide etwas davon.
Doch wenn die Fragen der Nutzenden bereits mit den Antworten in den AI Overviews beantwortet sind, dann gehst du doch leer aus. Oder? Das kommt darauf an, ob die Nutzenden wissen, dass die Inhalte von dir stammen (beispielsweise weil deine Brand genannt wird oder die Nutzenden sich die Quelle ansehen). So hättest du zumindest einen Branding-Effekt. Diese Überlegungen sind nicht neu, denn genau die gleiche Diskussion gab es schon mit der Einführung der Featured Snippets im Jahr 2014. Hast du dich damals also bereits entschieden, dass du eine Ausspielung in den Featured Snippets in Kauf nimmst, braucht deine Entscheidung hier nicht anders ausfallen. Das Aussperren von RAG-Crawlern scheint also wenig zielführend.
Bei den LLM-Crawlern sieht es jedoch anders aus. Diese werden hauptsächlich genutzt, um Trainingsdaten zu erhalten. Die tatsächlichen KI-Antworten werden meist durch aktuelle Daten unterstützt. Der Vorteil davon wäre, dass sich die Anzahl der Serveranfragen reduzieren kann. Wenn du also vor allem Inhalte Dritter auf deiner Website veröffentlichst (das ist z. B. bei Marktplätzen der Fall), dann bringt es dir nichts, wenn LLMs deine Daten auslesen.
Andersherum: Wenn du eine Publishing-Seite betreibst und komplett einzigartige Artikel veröffentlichst, möchtest du sicherlich nicht, dass diese zu Trainingszwecken genutzt werden. Hängt dein Erfolg aber wiederum von der Bekanntheit deiner Brand ab, dann könntest du alle Bots zulassen, da selbst die Nennung deiner Brand ohne Quelle einen Mehrwert für dich haben kann.
Zum Artikel aus 2023
ChatGPT sperren: So blockiert ihr die AI-Bots
26. September 2023
In einer Studie von Originality.ai wurde kürzlich bekanntgegeben, wie groß der Anteil der Top 1.000 Websites weltweit ist, die den GPTBot sperren.
Doch wie sieht das eigentlich in Deutschland aus? Diese Frage haben wir uns bei Claneo gestellt. Um dies herauszufinden, haben wir die genannte Studie adaptiert und uns die Top 1.000 Websites in Deutschland sowie die Websites der DESI250 angesehen.
Methodik:
- Identifikation der Top 1.000 Websites in Deutschland
- Analyse der DESI250
- Untersuchung der robots.txt jeder Website dahingehend, ob entweder der GPTBot, der ChatGPT-User oder der CCBot blockiert wurde
- Ausschluss von Websites aus der Analyse, die keine robots.txt haben oder wo diese nicht zugänglich war
- Erneute Wiederholung dieser Schritte drei Wochen später und Vergleich
Statistiken:
- Untersucht am 30.08.2023 und 22.09.2023
- 158 Websites untersucht (die anderen waren in beiden Listen enthalten)
- 129 robots.txt untersucht (die anderen Webseiten hatten keine oder es wurde zu diesem Zeitpunkt mindestens einer der Tests blockiert)
Warum ist das relevant?
Large Language Models (LLMs) brauchen Daten, aus denen sie lernen können. Dafür wurden in der Vergangenheit bereits diverse Quellen herangezogen, u.a. Wikipedia, Bücher, gecrawlte Webseiten.
Diese gecrawlten Webseiten basieren z.B. auf verlinkten URLs auf Reddit mit mindestens drei Upvotes, und auf dem Datenset der Non-Profit-Organisation Common Crawl. Dieser Bot crawlt wohl das gesamte Internet und da es hier bereits vorhandene Datensets gibt, ist die eigene Website vermutlich bereits dort enthalten. Bei dem User Agent von Common Crawl handelt es sich um den CCBot, der durch die robots.txt blockiert werden kann. Allerdings verhindert das nur, dass die eigene Webseite zukünftig durch den Common Crawler durchstöbert wird. Die bereits vorhandenen Daten gehen dadurch nicht verloren.
Auch OpenAI greift auf diese Daten zu, gibt aber außerdem an, dass sie in Zukunft eventuell selbst Webseiten crawlen werden, um künftige Modelle zu trainieren (Quelle: https://platform.openai.com/docs/gptbot). Ob das passiert oder nicht, ist noch nicht klar. Es ist jedoch möglich, den Crawler GPTBot von OpenAI ebenfalls in der robots.txt zu blockieren. Dies verhindert allerdings nicht, dass die Daten nicht aus anderen Quellen herangezogen werden.
Darüber hinaus gibt es für ChatGPT ein Plugin, welches das Internet durchsucht. Da ChatGPT nur mit Daten bis 2021 trainiert wurde, ist dieses Plugin insbesondere dann praktisch, wenn Nutzende aktuellere Daten benötigen. Auch dieses Plugin lässt sich durch die robots.txt blockieren, wenn die eigenen aktuelleren Inhalte dort nicht zu finden sein sollen. Ältere Daten bleiben hingegen weiterhin vorhanden. Hier heißt der User Agent ChatGPT-User.
Was kann also getan werden, wenn der eigene Website-Content nicht von künstlicher Intelligenz untersucht werden soll? Es gibt mehrere Anweisungen, die dafür in der robots.txt hinterlegt werden können. Keine davon bietet allerdings eine Garantie.
Konkret könnten also folgende Instruktionen in die robots.txt integriert werden, wenn all die genannten Bots vom Crawling ausgeschlossen werden sollen:
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: CCBot
Disallow: /
Es muss aber nicht die gesamte Website vom Crawling ausgeschlossen werden. So lassen sich auch nur bestimmte Bereiche der Webseite sperren, z.B. durch
User-agent: GPTBot
Disallow: /verzeichnis-4/
Neben den User-Agents gibt es auch die Möglichkeit, bekannt IP-Adressen vom Crawling auszuschließen. Das lässt sich für Außenstehende jedoch nicht nachprüfen und es muss regelmäßig sichergestellt werden, dass diese noch aktuell sind.
Sollte ich die KI-Crawler in der robots.txt wirklich aussperren?
Diese Entscheidung muss natürlich jede:r Website-Betreiber:in selbst treffen.
Die Idee dahinter: Wenn meine Daten nicht durch die KI bereitgestellt werden, dann landen die Nutzenden weiterhin auf meiner Webseite und ich kann weiterhin durch diese Nutzenden Geld verdienen.
Auf der anderen Seite fehlen diese Daten dann künftig in KI-generierten Inhalten – und das kann so weit gehen, dass zu einer Marke nur Daten Dritter als Quelle genutzt werden und keine eigenen. Ist das wirklich erstrebenswert?
Es gibt hier aktuell kein Richtig und kein Falsch. Es gilt jedoch herauszufinden, welchen Weg man mit der eigenen Webseite gehen möchte.
Wie viele deutsche Webseiten schließen die Crawler aktuell aus?
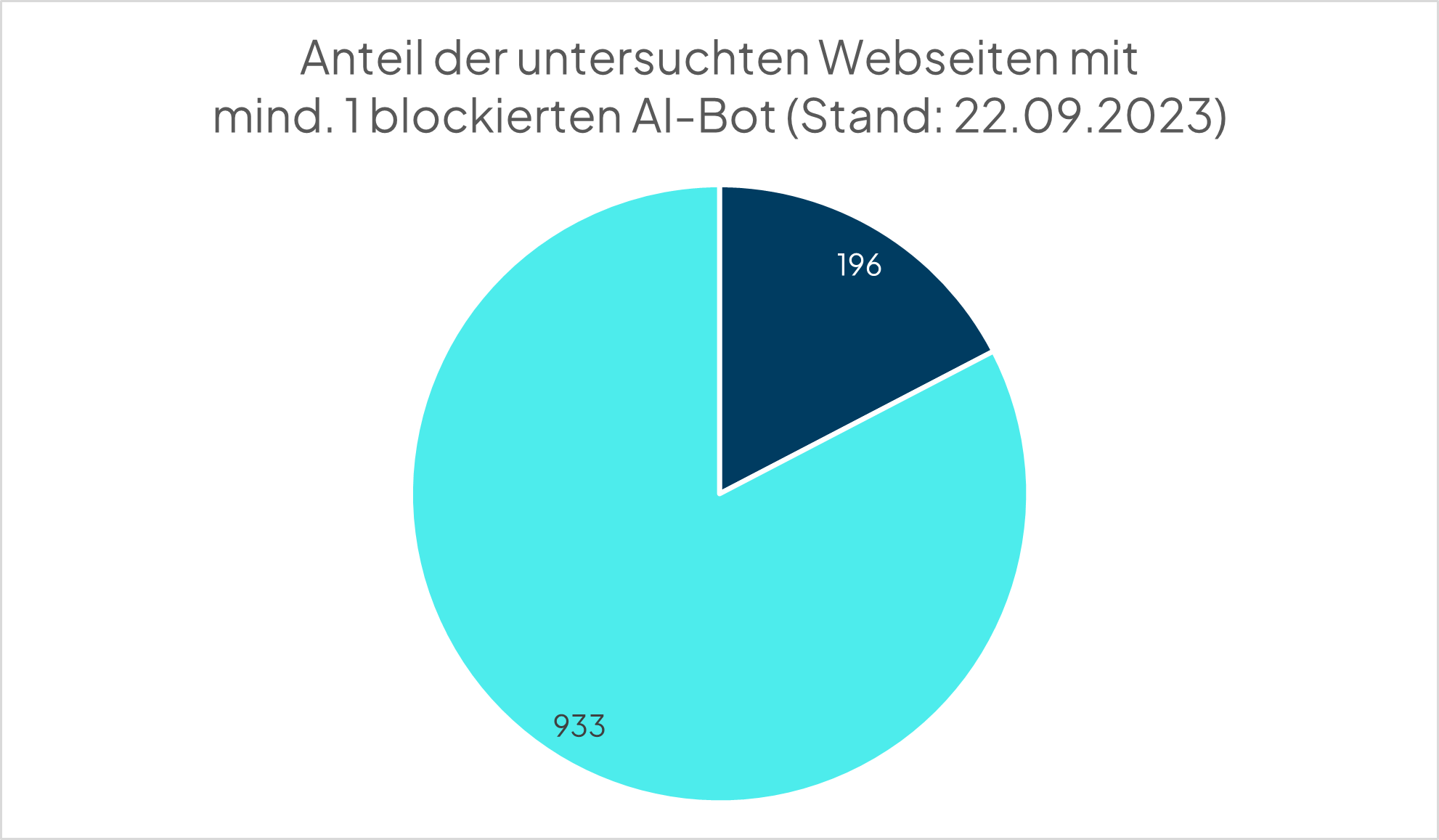
Insgesamt haben 17,4% der untersuchten robots.txt mindestens einen der untersuchten Bots blockiert (CCBot, GPTBot oder ChatGPT-User). Dabei waren es in der ersten Untersuchung nur 12,4%. Es ist also ein deutlicher Anstieg innerhalb von nur drei Wochen zu verzeichnen. In der o.g. weltweiten Studie waren es 18,6%. Diese Studie ist inzwischen allerdings auch ein paar Wochen alt und daher ist es nicht klar, ob der Anteil weiterhin aktuell ist.
Die Top-Webseiten (nach der Liste von DataforSEO) darunter sind:
- amazon.de (Platz 5)
- pinterest.de (Platz 11, im August wurde noch keiner der Bots blockiert)
- stern.de (Platz 23)
- sueddeutsche.de (Platz 25)
- welt.de (Platz 26)
- spiegel.de (Platz 29)
Im August gab es nur fünf Webseiten, die alle drei Crawler blockieren. Diese fünf Webseiten waren:
- glamour.de
- gq-magazin.de
- serienjunkies.de
- vimeo.com
- vogue.de
Im September waren es bereits zwölf Webseiten, die alle drei Crawler blockieren. Neu hinzugekommen sind mediamarkt.de, saturn.de, reuters.com, pharmazeutische-zeitung.de, fuersie.de, jolie.de und ok-magazin.de. Wobei reuters.com vorher bereits den CCBot und den GPTBot ausschloss, während die anderen sechs Domains zuvor gar keinen der untersuchten Bots ausgeschlossen haben.
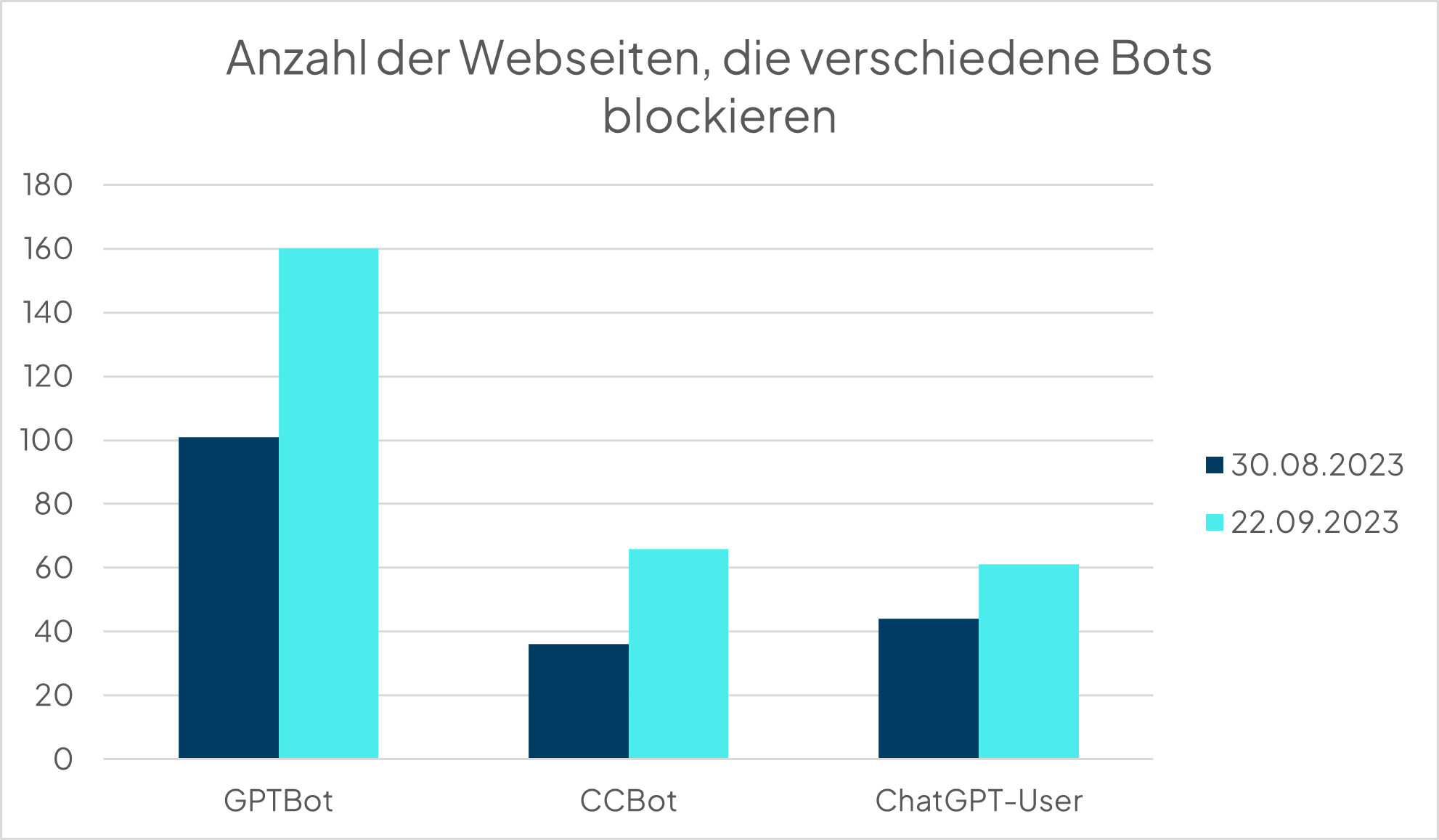
Der am häufigsten blockierte Crawler ist der von OpenAI (GPTBot). Immerhin 14,2% (im August waren es 8,9%) der untersuchten Webseiten blockieren diesen User Agent. Im August war der ChatGPT-User mit 3,9% der am zweithäufigsten geblockte User Agent. Im September stieg dieser Anteil auf 5,4%. Dagegen stieg der Anteil der Webseiten, die den Common Crawler blockieren von nur 3,2% im August auf 5,9% im September, sodass dieser nun der am zweithäufigsten geblockte Crawler ist.
OpenAI hat sich eventuell selbst ein Bein gestellt, als sie öffentlich bekannt gegeben haben, wie man den GPTBot in der robots.txt vom Crawling ausschließen kann. Die beiden anderen User Agents können zwar schon länger blockiert werden, dies setzen hingegen deutlich weniger Webseiten um.
Key Facts auf einen Blick
- 196 Webseiten blockieren mindestens einen der drei untersuchten Bots
- Der Anteil stieg innerhalb des Untersuchungszeitraumes um 40 %
- Zwölf Webseiten blockieren alle drei untersuchten Bots, wobei seit August sechs Webseiten dazugekommen sind, die vorher keinen der Bots blockierten
- 160 Webseiten blockieren den GPTBot (davon blockiert eine Webseite nur Teile der eigenen Inhalte)
- 66 Webseiten blockieren den CCBot
- 61 Webseiten blockieren den ChatGPT-User (davon blockiert eine Webseite nur Teile der eigenen Inhalte)
Das könnte dich auch interessieren:

Lydia Flügel



